on February 10, 2011 by in Under Review, Comments (0)
Introduction: Health informatics terminologies and related resources
Healthcare and medical terminology systems come in a sometimes bewildering variety of flavours and ‘standards’. Despite the similar names, there have been, and continue to be, a number of fundamentally different sorts of artifact – see “Related things easily confused with ontologies” in What is an ontology.
They have a history going back at least to the mid 19th century and, arguably, to the London Bills of Mortality published every Thursday from 1603 until the 1830s, a page of which is reproduced below.
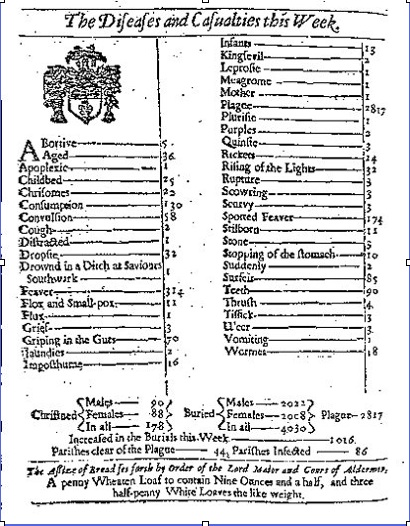
However, the real development started in the mid 19th century.
What following does not claim to be complete. (Please use the blog to comment and suggest additions for future versions). It aims to be a quick ready on major heathcare terminology resources, particularly for those from outside the medical field,. The organisation is a rough combination of purpose, prominence, and sponsoring organisation. Some of the artifacts described claim to be “ontologies”; others specifically deny being “ontologies”, and even amongst those that use the word “ontology”, the meaning varies.
A detailed report on the current state of terminologies around 2008 prepared for a “roadmap” for EU development in “Semantic Healthcare” is available at http://www.semantichealth.org/DELIVERABLES/SemanticHEALTH_D6_1.pdf
Families of General Health Informatics Terminologies, Classifications, and Ontologies
ICD and Related (International Classification of Diseases)
The ICD is the primary classification for international reporting of causes of death and disease (mortality and morbidity). It traces its roots to the 1860s when there was acute competition between a multiaxial French system developed by Marc D’Espine and a uniaxial English system developed by William Farr. Whatever the merits of the case, after 15 years or more of meetings English system was chosen and became the basis of what we now know as the International Classification of Diseases, which is used for almost all international recording of causes of death and forms the foundation for most disease classifications and terminologies. It is now maintained by WHO, is in its 10th edition, and is entering the revision to lead to its 11th edition planned to appear in 2011. The official reference to the official ICD WHO version is http://apps.who.int/classifications/apps/icd/icd10online/. It is also available for browsing from other sources including the National Center for Biomedical Ontologies’ BioPortal.
The official WHO ICD is organised in 22 chapters of which the first eighteen form the core, briefly: Infectious and parasitic diseases, Neoplasms, Diseases of blood and blood-forming organs, Endocrine, Behavioural, Nervous system, Eye, Ear, Circulatory, Respiratory, Digestive, Skin, Musculoskeletal, etc.
ICD is a “classification” rather than an “ontology”. The organisation is a rough combination of organisation, purpose, and prominence. To achieve this, ICD codes form a strict mutually exclusive and exhaustive monohierarchy. Each code must have exactly one parent, and all the children of a parent must completely cover all patients that fall under that heading.
ICD-10 codes represent the path from the root of the hierarchy to the code. They are of the form Ann.m, where the Ann part represents the heading condition and the number after the full stop indicates the specific detailed type. (In previous versions, the first character indicated the chapter, but some chapters have run over so that the system had to be changed.) For example, Chapter IX, “Diseases of the circulatory system, I00-I25”; I21, “Acute myocardial infarction”, I121.0, “Acute transmural myocardial infarction of the anterior wall”.
ICD has many additional features that have evolved over the years. There is an elaborate mechanism of annotations for coders of “excludes” and “includes”. There are two further volumes besides the primary hierarchy: one of precedence rules for choosing which diagnosis is the primary causes of death, and another that is an index, partly language specific, to help coders locate codes for words or phases that doctors may have used that do not correspond to the official name. There are also “residual” categories – i.e. “Not otherwise specified”, “Not elsewhere classified”, and “Other” required to meet the requirement that at each level the child classes be exhaustive. There is a cross referencing mechanism – the “dagger-asterisk” mechanism – that provides a primitive means for looking at diseases alternatively from an anatomical and aetiological point of view. The details of these features are beyond the scope of this article, but readers should be aware of their existence. The overall message is “Tread carefully when making assumptions about ICD.”
ICD, in its various forms, has a legal status in many jurisdictions. This fact, along with the desire to maintain continuity in international statistics, means that compatibility and stability are prime considerations in revisions. The requirement for continuity inevitably conflicts with demands for revisions to reflect changes in medical knowledge and to correct errors and omissions.
Closely related systems and special chapters
The main content of ICD10 is found in chapters I – XVIII. The remainder are in some ways special or auxiliary to the main purpose of international statistical reporting.
- Chapter XIX and XX (“Injury, poisoning and certain other consequences of external causes” and “External causes of morbidity and mortality”) form virtually a separate classification of “external causes”.
- Chapter XXI “Factors influencing health status”) forms another virtually separate classification.
- Chapter XXII (“Codes for special purposes” is a rag bag of information that must be coded in ICD for various purposes at least in some jurisdictions but does not fit elsewhere.
In addition, two other chapters have special characteristics:
- Chapter V of ICD on Mental illness is closely aligned to the DSM4 (and the emerging DSM5), the standard diagnostic system for psychiatry (see below).
- Chapter XVIII (“Symptoms, signs and abnormal clinical and laboratory findings, not elsewhere classified”) is involved primarily in uses in primary care and in auxiliary information rather than morbidity and mortality recording.
Finally:
- ICF – International classification of functions (formerly “ICIDH – International Classification of Functioning Disability and Health) – provides a listing for determining functional status rather than diagnosis – but is now being developed in conjunction with ICD-11
Clinical Modifications (CMs)
In addition, ICD has been adapted as a billing coding system in several countries including the US and Australia. The ICDxCM for “clinical modification” (or “CMA” for Australia) effectively adds an additional digit for subclasses of existing codes to get sufficient granularity for purposes of billing and remuneration.
SNOMED-CT and the Read Codes
SNOMED and the Read Codes come from very different backgrounds but have converged to produce SNOMED-CT, so are treated together.
SNOMED & SNOMED-RT
The ancestor of SNOMED was the Systematic Nomenclature of Pathology (SNOP), developed by Roger Côte and David Rothwell, and eventually managed by the College of American Pathologists. Unlike ICD, which had a single axis, SNOP organised information in four axes that could be freely combined, one term from each axis: anatomy (“topography”), morphology, etiology, and function. This basic structure was taken over when it was extended more broadly to medicine as a whole to become “SNOMED International”, a version of which is still used in France, French-speaking Canada, and parts of Germany. The system was highly flexible but unconstrained – it was possible to code an “inflammation” (morphology) of the “lung” (anatomy) caused by “pneumococcus” (aetiology), but it was also possible to code “Emotional changes” (morphology) of “blood” (anatomy) caused by a “donkey” (anatomy).
In the mid-1990s, the College of American Pathologists was convinced to create a scheme based on the description logic KREP, a variant of what would now be called EL++, to produce a “reference terminology” – SNOMED-RT. Major funding ($26M) was obtained, a large effort initiated.
The Read Codes / Clinical Terms Versions I, II, and III
In the mid 1980s, Abies Systems in the UK and James Read developed one of the early primary care systems based on recording four character codes, initially as a means of conserving disk space in an era when a 1MB floppy was “big.” The Read Codes version I were based roughly on the ICD organisation, with many enhancements to deal with signs, symptoms, and other issues relevant to British general practice. By the early 1990s, James Read had gained control of the codes and sold them to the UK government, along with an agreement to set up a Centre for Coding and Classification, which he headed. This embarked on a long effort to develop Read II – or 5 digit read – to cover all of medicine. The effort was ultimately defeated by the combinatorial explosion of terms, but the GP subset remains the standard coding system used by the majority of British GPs.
In the mid 1990s, the effort turned to Read III which was to be a radically more flexible system including modifiers and greater structure. Read himself left the project, which then became known officially as “Clinical Terms V3” or just “CTv3”. Before this effort could be completed, a merger with the SNOMED-RT effort was arranged, under which the two were combined to become SNOMED-CT. A few British general practices still use CTv3, but the major effort has shirted to SNOMED-CT.
SNOMED-CT
Overview
The result of the collaborative development of CTv3 and SNOMED-RT is SNOMED-Clinical Terms or SNOMED-CT. SNOMED-CT kept the basis in description logic from SNOMED-RT and developed and extended the delivery and identifier mechanisms and much of the content from CTv3. It was developed by the College of American Pathologists (CAP) through 2007 when it passed to a new International Health Terminology Standards Development Organisation (IHTSDO). The IHTSDO is supported by national subscriptions, and the system is free for users from subscribing countries, and for academic use and other specialised uses world-wide. Detailed information is available at www.ihtsdo.org and www.ihtsdo.org/snomed, where there are also means for support, reporting errors, participating in forums, etc.
SNOMED-CT currently comprises roughly 450,000 distinct “concepts” and over a million “terms” – i.e. labels for concepts. Each concept has a single “Fully specified term” and “preferred term”, but there are many synonym terms. Both Concepts and Terms have IDs, which have a rich internal structure allowing namespaces and allocation to subsidiary developers. IDs are never re-used but can be made obsolete. A standard for use of SNOMED is that the Term and ID are always quoted together, e.g. “Essential Hypertension|99042012”.
SNOMED is normally distributed as a set of files suitable for use on standard relational databases. Much of the authoring is done using a description logic equivalent to EL++. The “stated form” in KRSS notation is now distributed along with a PERL script that will convert it to OWL notation for loading into OWL tools.
SNOMED is currently mandated for use in the UK and for some purposes in the US, but the number of installations is still limited. Almost know one uses it “out of the box”, partly because of its enormous size, and partly because of the limitations in its curation. Most application developers create a “subset” for a particular purpose that they curate carefully. The full system, as delivered, continues to have numerous errors, ambiguities, easily confused terms and idiosyncrasies that make it unsuitable for use directly for most purposes except by those intimately familiar with its detailed construction. However, it undoubtedly provides the broadest coverage of any clinical vocabulary. Because of the legacy from primary care of the Clinical Terms (Read Codes), it is particularly rich in terms for signs and symptoms. Its anatomy axis is also well selected and contains a useful partonomy that has been taken as a starting point for numerous other systems. A major project is nearing completion to map SNOMED-CT to ICD-10CM, so that it can be used directly for recording information for billing in the US.
Pre-coordination, post-coordination, the problem of equivalence, and “Situations with explicit context”
Because SNOMED allows qualifiers – such as severity and site – it is potentially possible to express a notion such as “Fracture of the Hip” either as a single “pre-coordinated” term with a definition or as a compound “post-coordinated” expression consisting just of the expression in the definition without any label. The “problem of equivalence” is the problem of recognising the equivalence between a “pre-coordinated” term and “post-coordinated” expression (or between alternative logically equivalent post-coordinated expressions). The problem is important because, for historical reasons, many notions such as “Family history of Hypertension” have pre-coordinated terms in SNOMED, but such expressions exist only for the most common cases. Hence, software often provides both options, and the possibility of entries occurring in both forms needs to be dealt with.
A notable feature of SNOMED is that any term that is used in a negation, conjunction or qualified by a notion such as “history of…”, “family history of…” etc. appears under a “Situation with explicit context”. Therefore, subclasses of a disease must always be checked for in two locations, under the disease itself, and under “Situation with explicit context”. SNOMED provides no mechanism for doing this automatically, although the description logic could potentially make it easy to construct such queries.
Access to SNOMED
Access to SNOMED depends on what country you are in. However, for academic purposes, it is usually free to use. There are a variety of browsers, but the most widely used is ClinicClue Explore, which is kept up to date and allows download of up-to-date data.
Bibliographic systems – MeSH
The “Medical Subject Headings” (MeSH), maintained by the US National Library of Medicine, are for use in indexing Medline and PubMed (http://www.ncbi.nlm.nih.gov/pmc/) are the standard set of bibliographic headings for medical, and many biomedical, applications. MeSH is a thesaurus; it is explicitly neither a terminology nor an ontology. The hierarchical relation is “broader-than/narrower-than”. The numbering system indicates a path-name, but more than one path can terminate on the same term. There are, however, no identifiers other than path names and text terms.
For almost any application, one requirement will be to be able to cross reference to MeSH headings in order to be able to look up additional resources in PubMed/Medline.
Meta-thesauri – UMLS and the NCI Meta-thesaurus
The UMLS Metathesaurus
The US National Library of Medicine embarked in the early 1990s on the development of a cross referencing system amongst existing terminologies, no known as the Unified Medical Language System Metathesaurus. The UMLS cross references concepts from over a hundred classifications, coding systems, and terminologies (http://www.nlm.nih.gov/research/umls/). Use is free, but users must obtain and agree to licensing terms. In general, it is forbidden to extract an entire terminology or large fraction of a terminology – e.g. SNOMED – from the information in the UMLS, even though it might, in principle, be possible to do so. All resources are available either via a remote API or to download and mount locally (although to do so is a major task).
The key notions in UMLS are the “Concept Unique Identifier” (CUI) and the “Lexical Unique Identifier” (LUI). Each term has a Lexical Unique Identifier (up to certain normalisations for plurals, tenses, etc.). Each “Lexical Unique Identifier” (LUI) is associated with one or more “Concept Unique Identifiers” (CUI). Where more than one “Lexical Unique Identifier (LUI) is associated with the same “Concept Unique Identifier” (CUI), there is a case of synonymy; where more than one “Concept Unique Identifier” is associated with the same “Lexical Unique Identifier” (LUI) there is a case of polysemy.
Most importantly, UMLS terms from virtually all other terminologies and ontologies to MeSH, from which allows them to be used as entry points to PubMed/Medline. Any developer of any terminology would be well advised to ensure that there is a route for mapping their terminology to UMLS CUIs and LUIs to ensure that it can be used to access this critical bibliographic resource.
Other UMLS Knowledge Resources
Access to the UMLS also gives access to a range of other resources, many aimed at language processing.
- A Semantic Network (UMLS SN) of around 200 notions that provides high level categories for UMLS concepts. The Semantic Network is particularly adapted to linguistic usage.
- The “norming” software that is used to convert raw lexical strings to the lexical units that receive “LUIs”. This deals with a range of issues – tense, case, word order, etc.
- A range of other lexical tools that are free to download.
The NCI Thesaurus and Metathesaurus
The US National Cancer Institute (part of NIH – the National Institutes of Health) has developed its own “Thesaurus” – the NCI Thesaurus (NCIT) – implemented in OWL, which is in fact nearer closer to an “ontology” as the term is used in this book. It covers all cancers and related diseases, plus anatomy and various external factors. It forms the basis for the Enterprise Vocabulary Services (EVS) of the major software infrastructure CaBIG being developed and mandated by the NCI. The terminology in the NCI thesaurus is used, amongst other things, in the development and annotation of elements for CaBIG using the ISO 11179 standard for metadata registries.
As a separate artifact, but part of the same overall effort, the NCI has also developed the NCI Meta-thesaurus, which is similar in principle to the UMLS Metathesaurus but covers a different, although in places overlapping, set of resources and focuses on cancer specifically and linked into the EVS.
The NCI Thesaurus and Metathesaurus are particularly useful for translational medicine applications – i.e. those applications bridging molecular biology and clinical research and practice.
GALEN
GALEN (http://www.opengalen.org) is a generic ontology/terminology of clinical medicine developed in a series of European projects. It is almost certainly the most intricate large ontology of clinical medicine so far developed. It is no longer being actively maintained, but is available for mining for healthcare purposes and testing as a challenge to description logic reasoners. It was originally formulated in an early and somewhat idiosyncratic description logic, GRAIL (A. L. Rector, Bechhofer, S., Goble, C. A., Horrocks, I., Nowlan, W. A., and Solomon, W. D. 1997. The GRAIL concept modelling language for medical terminology. Artificial Intelligence in Medicine. 9, 139-171) that is roughly equivalent to EL++ but makes extensive use of role paths in ways that are not conformant to the OWL rules. It has recently been translated into OWL, although the last details related to role paths have yet to be resolved.
GALEN was used as the basis for the development of the French national classification of procedures and for parts of the maintenance of the Dutch procedure classification.
A major feature of GALEN was its use of an “intermediate representation”. in order to make it easy for authors, definitions were constructed by “dissecting” text descriptions of the procedures into a language that was relatively easy for users but could be translated directly into GRAIL. The goal was that users could be come proficient with no more than three days’ training, and in this the project was largely successful. (For details see A. L. Rector, Zanstra, P. E., Solomon, W. D., Rogers, J. E., Baud, R., Ceusters, W., W Claassen, Kirby, J., Rodrigues, J.-M., Mori, A. R., Haring, E. J. v. d., and Wagner, J. 1999. Reconciling users’ needs and formal requirements: Issues in developing a re-usable ontology for medicine. IEEE Transactions on Information Technology in BioMedicine. 2:4, 229-242.)
GALEN was based on a well developed upper ontology emphasizing the interaction between casual and part-whole relations and subsumption and dealt with a wide range of pragmatic issues in reconciling conflicts between the pragmatics of common medical usage and the rigorous logic in the description logic. (A. L. Rector and Rogers, J. E. 2006 Ontological and practical issues in using a description logic to represent medical concept systems: Experience from GALEN. In Reasoning Web, P. Barahona, F. Bry, E. Franconi, N. Henze, and U. Sattler,Eds Springer-Verlag)
Specialised Terminologies and Classifications
There are myriad specialist terminologies, classifications and ontologies in medical subfields. Perhaps the best way to get an up-to-date list is to look at the UMLS Knowledge Sources. Two areas of particular important are:
- Nursing – where there are two competing terminologies:
- ICNP (http://www.icn.ch/icnp.htm)
- NANDA (http://www.nanda.org/)
- Radiology – where there are a number of terminologies, where the standard is part of the DICOM image transfer / messaging standard. In its long history it has previously been known as “ACR NEMA” and now subsumes what was even earlier called the “SNOMED-DICOM Microglossary” (which had little to do with SNOMED despite its name)
Interaction with Electronic Health Records and Messaging
A key function of health informatics terminologies and ontologies is to interact with Electronic Health Records (EHRs). The one cannot be understood without some knowledge of the other. The topic of EHR formats is a complicated and confusing area in its own right. The links below give at least a starting point for further investigation. The coding system LOINC is included here because of its close association with the HL7 messaging standard.
LOINC
Most laboratory information is exchanged using the LOINC codes – “Logical Identifier Names and Codes” – (http://loinc.org/) The LOINC codes are an open source set of codes that developed alongside the standard data interchange format messaging between clinical systems, HL7. (see below). The codes are a multipart expressions best understood by consulting the user manual and other information on the LOINC site.
HL7
HL7 – “Health Level 7” (referring originally to a seventh level over the then standard ISO 6 layer model) (http://www.hl7.org) is the most widely used interchange standard for clinical systems. It is a messaging system rather than a health record system, but the line is often blurred in practice. It supports two different interchange schemes:
- V2 – is a bar delimited format for expressions defined in ASN.1, which, along with the LOINC codes, is almost universal for communication with laboratory equipment in hospitals along with the LOINC codes.
- V3 – is a much more elaborate system developed on the basis of a “Reference Information Model” (RIM) over the past decade and a half, but implemented to only a limited degree, most widely in the UK as part of the NHS National Programme for IT. V3 is agnostic concerning its use of coding system, but many parts have been designed with SNOMED-CT in mind.
Although described as “versions”, V2 and V3 have almost nothing in common except their common aspiration to improve the interworking of clinical information systems. In addition the “Clinical Document Architecture” (CDA) section of HL7 v3, is virtually a separate scheme on its own and often referred to separately (http://www.hl7.org/implement/standards/cda.cfm). To add to the confusion CDA also exists in two versions. Version 2 is nominally compliant with the RIM, but much simpler in practice, and supports coded entries. Version 1 is largely a mechanism for structuring free text entries.
HL7 maintains its on Vocabulary group that manages the “vocabulary domains” (https://www.hl7.org/library/data-model/RIM/C30202/vocabulary.htm) and Common Terminology Services and API (http://informatics.mayo.edu/LexGrid/index.php?page=ctsspec). The vocabulary group is concerned both with establishing specific “structural” vocabularies needed internally by HL7 and with selecting and establishing the interface to externally defined terminologies such as SNOMED and LOINC.
CEN 13606, OpenEHR, and Archetypes
The most widely used standard for medical records, per se, at least in Europe is CEN 13606 (http://www.en13606.eu/) which is a simplification of the OpenEHR architecture (http://www.openehr.org/home.html). (CEN is the European Standardisation Committee, parallel to ISO internationally.) Both CEN 13606 and OpenEHR use the Archetype formalism (http://www.openehr.org/svn/specification/TRUNK/publishing/architecture/am/archetype_principles.pdf), a data structuring format designed specifically for medical records. From the point of view of terminology, the most important feature of Archetypes is that they never refer to terminology directly. Rather each Archetype has an “Ontology section” that links an internal name to an external reference. Note that the “ontology section” is not an ontology in itself, rather a means of redirecting terminology from the Archetype to other resources. It is therefore a form of “Terminology Binding” (See A. Rector, Qamar, R., and Marley, T. 2009. Binding ontologies and coding systems to electronic health records and messages. Applied Ontology. 4:1, 51-69. pdf)
Tags: Alan Rector, Healthcare Terminologies, life sciences, thesauri
No Comments
Leave a comment
Login