on January 22, 2010 by in Under Review, Comments (3)
Resource Description Framework (RDF)
Introduction
This post provide a brief overview of the Resource Description Framework (RDF). RDF is a W3C recommended standard for publishing data on the Web and is one of the core technologies of the Semantic Web. A comprehensive description of the RDF specification is available from the W3C here
The Resource Description Framework (RDF) provides a common data model for publishing data on the Web. The data model itself is relatively simple and can be used to create statements about resources, a resource can refer to any object that you might want to describe on the Web. RDF is primarily aimed at providing meta-data to data being published on the Web, for example, RDF can be used to add structured information about a web page, such as its creator, creation date and title. In addition, more applications are using RDF as model for representing data, for example, in the emerging Linked Data Web
The RDF data model describes a graph where the nodes represent resources and the edges represent named links between resources. The graph is a collection of triples where each triple forms a statement with a subject, predicated and object (See Figure 1). The subject of the triple is the resource we want to describe, the object is the resource we want to relate to the subject and the predicate provides the relationship between these two resources.
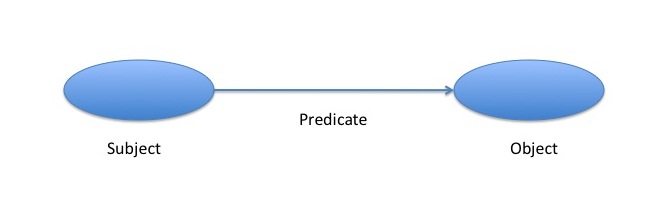
For example, RDF could be used to create a statement about this article. The subject of the statement would be the actual web page, the predicate used will be named creator, and the object would refer to the creator, in this case it will be reference to a person called Joe Blogger.

In addition, more RDF could be used to add additional statements about this page such as its creation date, title and version information. The object of a triple statement can be either another resource or a literal value, such as a string or number. For example, we could describe the version of the web page using a literal value for the object of the triple.

RDF adopts another Web based technology in order to specify and identify resources on the Web. Each resource is identified by a Uniform Resource Identifier (URI). URIs provide a mechanism to assign unique identifiers to resources on the web. URIs can look similar to a Uniform Resource Locator (URL), but whilst a URL is used to locate an actual resource on the Web, such as web page, URIs don’t always refer to a physical resource. We could conveniently reuse the URL for this page as the URI for this resource: http://ontogenesis.knowledgeblog.org/2010/01/22/resource-description-framework-rdf.
In RDF, the predicates are also treated as resources on the Web, so are identified using URIs. For example, the Dublin Core (DC) initiative provides a set of predicates for adding meta-data about web pages, the DC URI for stating the creator of this page is http://purl.org/dc/terms/creator. Conforming to standards such as DC improves the interoperability and exchange of data between applications on the Web.
URIs are not constrained to web object alone, but can be used as a reference to any type of conceivable object. This includes people and places, so one can assign a unique URI to themselves as way of identifying them on the web. We can create a resource that refers to the author of this page, once we have a URI for this individual we can add additional RDF statements about his name, address, date of birth etc..
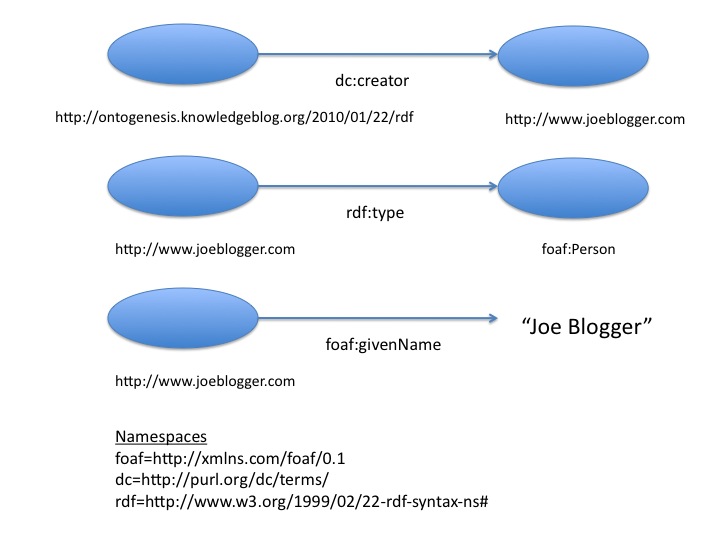
The figure above depicts three RDF triples, the subject of the first triple is this actual blog post which is connected to a creator using the Dublin Core creator predicate. The creator of the article is itself a resource and has its own URI. The second statement uses the rdf type predicate to assert that this resource is a type of Person. The final statement uses a literal value to assign a value to the name of this person.
Serialisation and Syntax
In order to actually publish RDF statements on the Web you need a syntax. There are several syntax available for representing RDF. The reference syntax proposed by the W3C for RDF is RDF/XML. Other syntax, such as Turtle and N3, are intended to be more concise and human readable. See more on RDF syntaxes here<Matts syntaxes bit>.
Querying, tools and APIs
RDF Extensions
The simplicity and flexibility of RDF make it an attractive data model for publishing data on the web. Having all this data in some computational form enables application developers to treat the web as a large database, where data can be queried and manipulated in-situ. RDF has gained particular attention from the knowledge representation community as a means of capturing and sharing a wide range of knowledge. Data intensive fields such as medicine, life sciences and astronomy are looking to exploit RDF technology as a way to integrate and share large volumes of data.
The knowledge representation community have provided additional requirements for technologies that build on top of RDF in order to provide a richer vocabulary for describing data. These vocabularies also provide additional semantics that enable the data to be interpreted and processed more intelligently by a computer. The main schema language built on top of RDF is RDF Schema (RDFS). RDFS defines the vocabulary used to make statements about a particular domain and can also be used to describe the relationships between these objects. For example, RDFS allows us to describe classes of objects, such as People and Places and put constraints on the relationships between these classes. Many data models are emerging that can be serialised into RDF, one notable example is the Web Ontology Language (link to main OWL article)
Review of Resource Description Framework (RDF) | Ontogenesis
January 22, 2010 @ 1:18 pm
[…] This is a review of http://ontogenesis.knowledgeblog.org/2010/01/22/resource-description-framework-rdf/. […]
Blogging an Ontology Book « Thoughts on ontology in bioinformatics
January 22, 2010 @ 2:24 pm
[…] is an Ontology? Upper ontologies OWL RDF Application and reference ontologies Community dirven ontology development Protege and Protege OWL […]
Reification of properties in an ontology | Ontogenesis
December 18, 2010 @ 3:21 pm
[…] knowledge representation languages such as RDF directly support reification. However, OWL does not allow the ontologist to qualify properties in […]