on August 15, 2013 by in Under Review, Comments (0)
Modelling in multiple dimensions is great in so many ways
Overview
We describe what multi-dimensional modelling is, why it’s good for you, and how it works in OWL.
The Authors
Uli Sattler and Robert Stevens
Information Management and BioHealth Informatics Groups
School of Computer Science
University of Manchester
Oxford Road
Manchester
United Kingdom
M13 9PL
sattler@cs.man.ac.uk and robert.stevens@Manchester.ac.uk
Multi-dimensional modelling
When modelling a domain, we often find that there are many aspects to be considered, and many things to be said when describing the concepts relevant in this domain. As a result, we’d expect to see a concept at many places in the ontology’s hierarchy, or have many routes through the hierarchy to reach a concept. For example when talking about animals and cats, we can talk about their location in the taxonomy, what they eat, their anatomic structure, where they live, etc. Trying to squeeze these aspects into a single hierarchy is at least difficult – and may lead to a large and unwieldy model. Pulling these aspects or dimensions apart, modelling these dimensions separately, along with the relations between them, then putting them back together again is what OWL and reasoners have been designed to support: OWL supports us in modelling, say, animals, their habitat, prey, food, anatomy, etc. and the relations between them like lives in or eats.
Assume you want to model documents about animals. Then of course we distinguish the document dimension and the animal dimension, and structure the concepts in each of them hierarchically. For the animal dimension, we can consider standard classes such as mammals, feline, cat, etc., and for the document dimension, we can consider books, collections, articles, etc.
One thing we can observe is that we have both is-a or subsumption relationships, e.g., between collection and book, and between feline and mammal, but also other relationships, e.g., a collection contains some articles (and it is not the case that an article is-a collection), and that a cat eats some mouse.
Also, there are loads of other dimensions that would be useful to model which are neither document nor animal, e.g., contributors, authors, editors, (publication) time, target audience, etc. about documents, as well as habitat, bodyparts, diet, etc., about animals. And again, the relationship between, say, a document and it’s audience isn’t is-a, and neither is that between a leg and an animal.
Next, we will see how we can build models that faithfully represent these different dimensions, and what the benefit of doing so is.
Multi-dimensional modelling in OWL
In OWL, first of all, we can model is-a, namely via subclass. Hence we would start with introducing a class name for the top level of each of our dimensions, and then add other relevant class names as subclasses.
Class: Document Class: Animal Class: Bodypart Class: Habitat Class: Readership Class: Food Mammal SubClassOf: Animal Feline SubClassOf: Mammal Rodent SubClassOf: Mammal Mouse SubClassOf: Rodent Book SubClassOf: Document Article SubClassOf: Document Arm SubClassOf: Bodypart Trunk SubClassOf: Bodypart Children SubClassOf: Readership Desert SubClassOf: Habitat |
Second, we can link dimensions via properties. We can start by introducing domains and ranges of these properties. This isn’t required, but it will usefully cause errors – namely an unsatisfiabilities – in case we use properties on classes that they weren’t designed for. For the examples below, please note that the range of about here is Animal since we consider documents about animals only – in general, this range should be rather Topic.
Property: about
Domain: Document
Range: Animal
Property: writtenFor
Domain: Document
Range: Readership
Property: eats
Domain: Animal
Range: Food
Property: livesIn
Domain: Animal
Range: Habitat
Property: has
Domain: Animal
Range: Bodypart
|
Thirdly, we can describe classes and individuals in terms of where they sit in this multi-dimensional space.
ChildrensBook EquivalentTo: Document and (writtenFor some Children) DesertCat EquivalentTo: Cat and (livesIn some Desert) Cat SubClassOf: Feline and (eats some Mouse) Elephant SubClassOf: Mammal and (has some Trunk) Carnivore EquivalentTo: Animal and (eats some (Animal or (inverse(has) some Animal))) myFavBook Types: Book, (about some (Cat and livesIn some House)), about value Kitty Kitty Types: Cat and (eats some Grass) and (eats some (inverse(has) some Animal)) |
In these descriptions, we can distinguish between necessary conditions – described via SubClassOf – and necessary and sufficient conditions – described EquivalentTo. And we can use complex class expressions both to describe the types of individuals and classes.
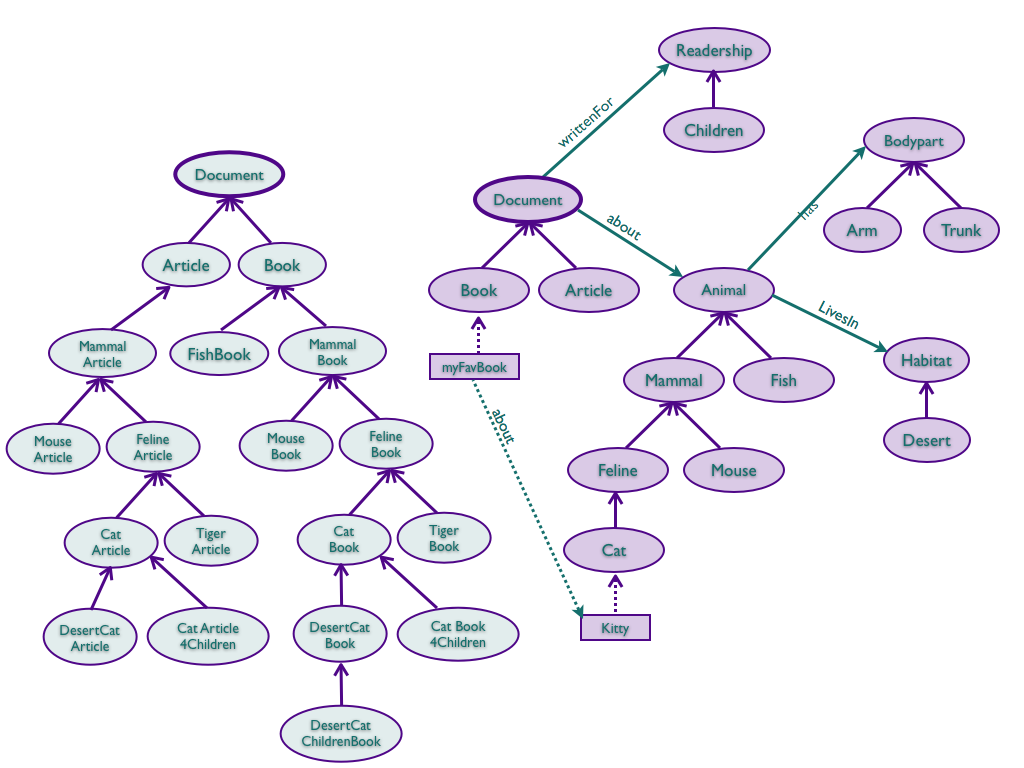
Figure 1. A picture showing a possible hierarchical structure of our documents, and one of our ontology with the dimensions separated out
Then of course we can ask a reasoner to classify our ontology and infer classes that our individuals are instances of. For example, we can infer from our example ontology that Cat is a subclass of Carnivore and that Kitty is a Carnivore. this pulling apart of different dimensions into their own hierarchies, then relating a class of objects to its dimensions via properties, then building a polyhierarchy by using defined classes is the technique advocated in ontology normalisation.
Advantages of Multi-dimensional modelling in OWL
First, by separating the different dimensions we want to talk about in our ontology and relating them via suitable properties, we can build an informed model of our application that reflects the different kinds of things that we want to talk about and the different relations between these. For example, we can distinguish between the things that animals eat, that they hunt, and that they play with. And we can distinguish the audience a document was written for from the one it is then read by or the one that it is advertised to. OWL also allows us to relate properties to reflect relations between properties: we can use hunts SubPropertyOf eats to state that things hunted by an animal are also eat by it, but not necessarily vice versa (clearly, we wouldn’t want, say, carrots to be hunted – but we also may want to describe scavenging animals).
Secondly, these nicely separated dimensions can be readily re-used; we can take our hierarchy of habitats and use it somewhere else too. More importantly, we are free to reuse existing (sub)ontologies to describe some of these dimensions; e.g., if we were really interested in building an ontology for documents about animals, we would be foolish not to reuse existing animal ontologies for the animal dimension (and possible others as well).
Thirdly, in our experience, this style of modelling not only leads to clearer, but also smaller ontologies: rather than having one big hierarchy where subhierarchies get multiplied, we keep those subhierarchies separate and simply relate to them via properties. For example, we will have one hierarchy of animals – rather than a hierarchy of animals by habitat and another one by feeding habit, and then a hierarchy of books by animals by habitat and another one by animals by feeding habit.
Fourthly, the multi-dimensional modelling can be nicely exploited by post-coordination: as in the examples above, we can describe (the type of) individuals via complex class expressions and we can also relate them to each other via properties. All this is then being taken into account when classifying them (i.e., determining the named classes an individual is an instance of), and we can also exploit this in tools where we filter individuals, either on named classes or complex class expression. This allows us to generate different views of our ontology: we can simply view/expose/export the (inferred) class hierarchy or relevant subtrees thereof (e.g., subclasses of Document), or we can generate a multi-dimensional view that allows us to browse simultaneously through the different dimensions of our ontology, see our N8 ontology browser for a small example.
Finally, separating a domain of interest out into its different dimensions is what ontology modelling is all about.
No Comments
Leave a comment
Login